2023 Databases for Serverless Applications
So what’s the deal with serverless and edge compute? Well, basically, they’re ways of running applications without having to worry about managing servers. This is great for developers because it means they can focus on building cool stuff instead of worrying about infrastructure.
But what does this have to do with databases? Well, if you’re not managing servers, then you need a way to store your data. And that’s where databases come in.
There are a lot of different databases out there, but not all of them are created equal. Some databases are better suited for serverless and edge compute than others.
So which databases are the best for serverless and edge compute? That’s what I’m here to talk about today.
I’m going to give you a quick overview of some of the best databases for serverless and edge compute. I’ll also tell you a little bit about each database and why it’s a good fit for serverless and edge compute.
What is a Serverless Database
Did you know that the first relation database was created in 1970?!? Now comes the part where I feel really old in telling you that the first database that I used was MySQL on a MAMP stack back in 2001.
Okay enough nostalgia!
In the last 10+ years we started to build everything on the web in a serverless world, except for our databases. We no longer need to stand up a server, or even a VM to deliver a great website, except for when it comes to data. We are just now coming to realize that we need to create serverless-first storage solutions.
What criteria must be met to be considered serverless?
Connectionless
Connectionless databases are the way to go for developers who want to focus on building their applications, not managing database connections.
Traditional database protocols are stateful, which means that they keep track of the state of the connection between the client and the server. This can be a problem for developers who want to scale their applications to zero compute, because it means that they need to keep track of a lot of connections that are not being used.
HTTP, on the other hand, is a stateless protocol. This means that the client and the server do not need to keep track of the state of the connection. This makes it much easier to scale applications to zero compute, because the server can close connections that are not being used.
Connectionless databases provide an abstraction over connection pooling. This means that developers can use connectionless databases without having to worry about managing connections themselves. The database will automatically open and close connections as needed, which frees developers up to focus on their applications.
Here are some of the benefits of using connectionless databases:
- Simplicity: Connectionless databases are much simpler to use than traditional database protocols. This is because developers do not need to worry about managing connections themselves.
- Scalability: Connectionless databases are much more scalable than traditional database protocols. This is because the server can close connections that are not being used, which frees up resources for other connections.
- Performance: Connectionless databases can often perform better than traditional database protocols. This is because the server does not need to keep track of the state of the connection, which can improve performance.
Web Native
A web native database is a database that is designed to be used with web applications, think of this simply in terms of allowing the use of fetch(). It is typically stored on the web server and is accessed by web clients using a web browser. Web native databases are often used for storing data that is used by multiple users, such as user profiles, product catalogs, and order information. Utilizing either HTTP APIs or WebSockets rather than connecting directly.
When choosing a web native database, it is important to consider the following factors:
- The amount of data that will be stored
- The number of users who will be accessing the database
- The type of data that will be stored
- The level of security required
Web native databases offer a number of advantages over other types of databases, including:
- Scalability: Web native databases can be scaled to meet the needs of growing applications.
- Performance: Web native databases are typically very fast and efficient.
- Security: Web native databases can be secured using a variety of techniques.
- Cost: Web native databases are typically very cost-effective.
Lightweight
One of the key benefits of lightweight databases is that they can help to reduce complexity. In the past, developers had to worry about a lot of the details involved in managing a database, such as setting up and configuring the database server, creating and managing user accounts, and ensuring data security. However, with lightweight databases, many of these tasks are handled by the database vendor. This can free developers up to focus on their core application logic, which can lead to faster development times and lower costs.
Another benefit of lightweight databases is that they are often more scalable than traditional databases. This is because they are typically designed to be distributed across multiple servers. This can help to ensure that applications can continue to perform even under heavy load.
Here are some additional details about how complexity is shifting to the database vendor:
- Database vendors are increasingly providing tools and services to help developers manage their databases. This includes features such as automatic backups, data replication, and security management.
- Database vendors are also working to make their databases more self-service. This means that developers can perform tasks such as creating and managing user accounts, and configuring database settings without having to contact the database vendor.
- The shift of complexity to the database vendor is a positive trend for developers. It frees them up to focus on their core application logic, and it can help to reduce the overall cost of database management.
Developer eXperience
No one wants to remember how to query a database using SQL (okay maybe a few of you), so it is very important to keep your users writing statements that are in their native language for the majority of users that means TypeScript. If you are working on large applications that have several people included automating the task of type safety is a must! Luckily their are many companies stepping up to the challenge in this area like Prisma, Kysely, Drizzle, Contentlayer, and Zapatos. These tools will make your DX super easy and remove lots of nasty 🐞‘s from your code!
Solutions
It isn’t as easy anymore to just say we are going with Postgres, MySQL or MongoDB. There are tons of choices out there already that include or wrap these databases, and there are tons of options coming out that include some awesome future features. So how can one decide? I will break these down into the buckets that have the most feature parity along with general availability (aka won’t be a flash in the pan).
Established Backend as a Service
The BaaS platforms are really unique in that they have so much of the authentication and authorization baked into each one of the products. You often able to customize the database (and other resources) down to the data level.
I am a Firebase GDE and I still consider Firestore to be an amazing product and very well established being more than 5 years old now. Firebase provides built-in support for Authentication, Remote Config, Cloud Functions, Cloud Messaging, Cloud Storage and Hosting. Every Firebase project is a Google Cloud Platform project and can extend its reach in incredible ways.
I am also an AWS Community Builder focusing on Front-End Web & Mobile. The AWS Amplify product includes DynamoDB which is a fast, flexible NoSQL database service for single-digit millisecond performance at any scale. Utilizing all of the services within Amazon Web Services (AWS) portfolio is amazing powerful. AWS Amplify includes Authentication, PubSub, Functions, Push notifications, and Storage. All of this while using Cloud Formation for IaC to make changes easily (although at times slow) and consistent across environments.
Appwrite is an open source alternative to the above mentioned products, it can be loaded with a simple docker compose command anywhere docker runs. Full disclosure I was a Developer Advocate for them as well. Everything in Appwrite is written in PHP but like the others provides a host of different SDK's for both web and mobile. As of writing this the database powering the default solution is MariaDB. One of the unique abstractions that Appwrite provides is that it allows really for any database type and I am sure the team will add Postgres in the near future. Appwrite also includes Authentication, Storage, and Functions. Appwrite's realtime is not built into the connection like Firestore, but it makes it easy to get any events across the entire system not just the database which is really awesome!
Of course if I am writing about Appwrite I need to also talk about Supabase. Supabase hasn't been around as long as Firebase and AWS Amplify, but it has won the hearts of developers. It includes a Postgres Database along with Authentication, Storage, Realtime and Edge Functions.
Unlike the solutions above MongoDB actually positions its Atlas product as a "data platform". As you can read in their blog Why Serverless is the Architecture Developers Have Been Waiting For MongoDB is positioning itself really well with the MongoDB Atlas Serverless product!
Serverless Solutions and Databases
Some of these might include full BaaS, but are too new to put into an established list. Others have not figured out who they want to be yet. Then there are those who know who they are and just offer a database.
MySQL
If you love MySQL I am sure you have heard of PlanetScale! It replaces a lot of tech, and includes Vitess. The Query Monitoring alone make this one of my favorite picks!
Postgres
AlloyDB is pushing performance forward with 4x faster than standard PostgreSQL for transactional workloads and 100x faster analytical queries. Although still in preview AlloyDB Omni is a downloadable edition of AlloyDB designed to run anywhere. Which means that you can use it to run at the edge with serverless solutions!
AWS Aurora was one of the first serverless Postgres offered and continues to be a very cost effective, highly scalable solution.
CockroachDB Serverless is a fully managed service that automatically scales up and down based on demand, and it provides a high level of availability and durability. The service is also compatible with PostgreSQL, so developers can use their existing skills and tools to build applications on CockroachDB Serverless.
EdgeDB has one of the dopest database animations using three.js, make sure you checkout their homepage! EdgeDB came up with something called a graph-relational database, it still uses Postgres query engine under the hood but it makes you think in an object-oriented data model which I absolutely love!
module default {
type Account {
required property username -> str {
constraint exclusive;
};
multi link watchlist -> Content;
}
type Person {
required property name -> str;
link filmography := .<actors[is Content];
}
abstract type Content {
required property title -> str;
multi link actors -> Person {
property character_name -> str;
};
}
type Movie extending Content {
property release_year -> int32;
}
type Show extending Content {
property num_seasons := count(.<show[is Season]);
}
type Season {
required property number -> int32;
required link show -> Show;
}
};Neon is on fire ever since Introducing storage on Vercel. Neon is Postgres built with the first serverless SQL database for the frontend cloud. You can see from their diagrams about branch preview deployments that they truly have DX figured out!
Supabase has everything you would need for a full BaaS solution including database, auth, storage and more. On top of that with their latest series B they are now moving to the third phase (sounds a lot like a MCU movie) where they will be working on Ephemeral compute and scaling down to zero when it's unused.
If you are looking to store time series data, Timescale is the perfect. It takes Postgres to the next level for both transactional and analytical workloads. It has features like policies for automated data aggregation, downsampling and retention.
Redis
Upstash makes serverless Redis so darn easy is freaky! See the below code snippet. They also offer Kafka and QStash as well, which makes a solid argument for using them for all your serverless data requirements.
import { Redis } from '@upstash/redis';
const redis = new Redis({
url: 'https://obi-wan-kenobi-31346.upstash.io',
token: 'TOKEN'
});
const data = await redis.set('foo', 'bar');SQLite
If you 💜 GraphQL then you will for sure like Grafbase. It combines your data sources into a centralized GraphQL endpoint. This is also a great solution for branch preview deployments! If you run in `dev` it will spin up sqlite database, but in reality you can wrap these with any auth and database solutions.
Turso is really cool, you can write a TypeScript Class and it will generate an API. Turso is an edge-hosted distributed database based on libSQL, which is the open-source and open-contribution fork of SQLite. You can find a lot more detail in this great tutorial by James Sinkala Early impressions of Turso, the edge database from ChiselStrike.
Other
Fauna is the only distributed serverless cloud database that combines the flexibility of NoSQL systems with the relational querying and ACID consistency of SQL databases. It is super similar to Firestore with some important differences. We had a great chat with Rob Sutter all about it in our Podcast Scaling Transactional Data Globally with Fauna, make sure to check it out!
Ably is a slightly different than the other solutions in post, as it provides highly scalable realtime solutions. These include Live Chat, Multiplayer Collaboration, Data Broadcast, Data Syncronization, and Notifications. What is really cool about this is that you can have you data storage and processing in your backend and Ably can provide all of hte pub/sub and state persistence needed across a global edge network.
Convex is a web developers dream when it comes to Type Safety! Now that I said the best part it also includes functions, file storage, scheduling, search and realtime updates.
Hasura offers an "Instant GraphQL" on all your data. The power with Hasura is in how many databases are already supported! Including CockroachDB, Neon and Supabase!
If you are looking to add presence or collaboration into a document liveblocks makes it amazingly simple! Checkout the below code, you get this amazing cursor presence across your application! They also have document browsing, permissions management and database synchronization.
import { createClient } from '@liveblocks/client';
const client = createClient({
/* ... */
});
const room = client.enter('my-room', {
initialPresence: { cursor: null }
});
document.addEventListener('pointermove', (e) => {
room.updatePresence({
cursor: { x: e.clientX, y: e.clientY }
});
});
document.addEventListener('pointerleave', (e) => {
room.updatePresence({ cursor: null });
});
room.subscribe('others', (others) => {
// On client A: [{"cursor":null}]
// On client B: [{"cursor":null}]
/* re-render cursors based on others presence */
});NHost is much like Firebase and Appwrite, but everything is in GraphQL. It is built on top of Hasura, Postgres and S3. Being a Firebase GDE and working for Appwrite in the past I might be a little biased here, so I will leave this at that.
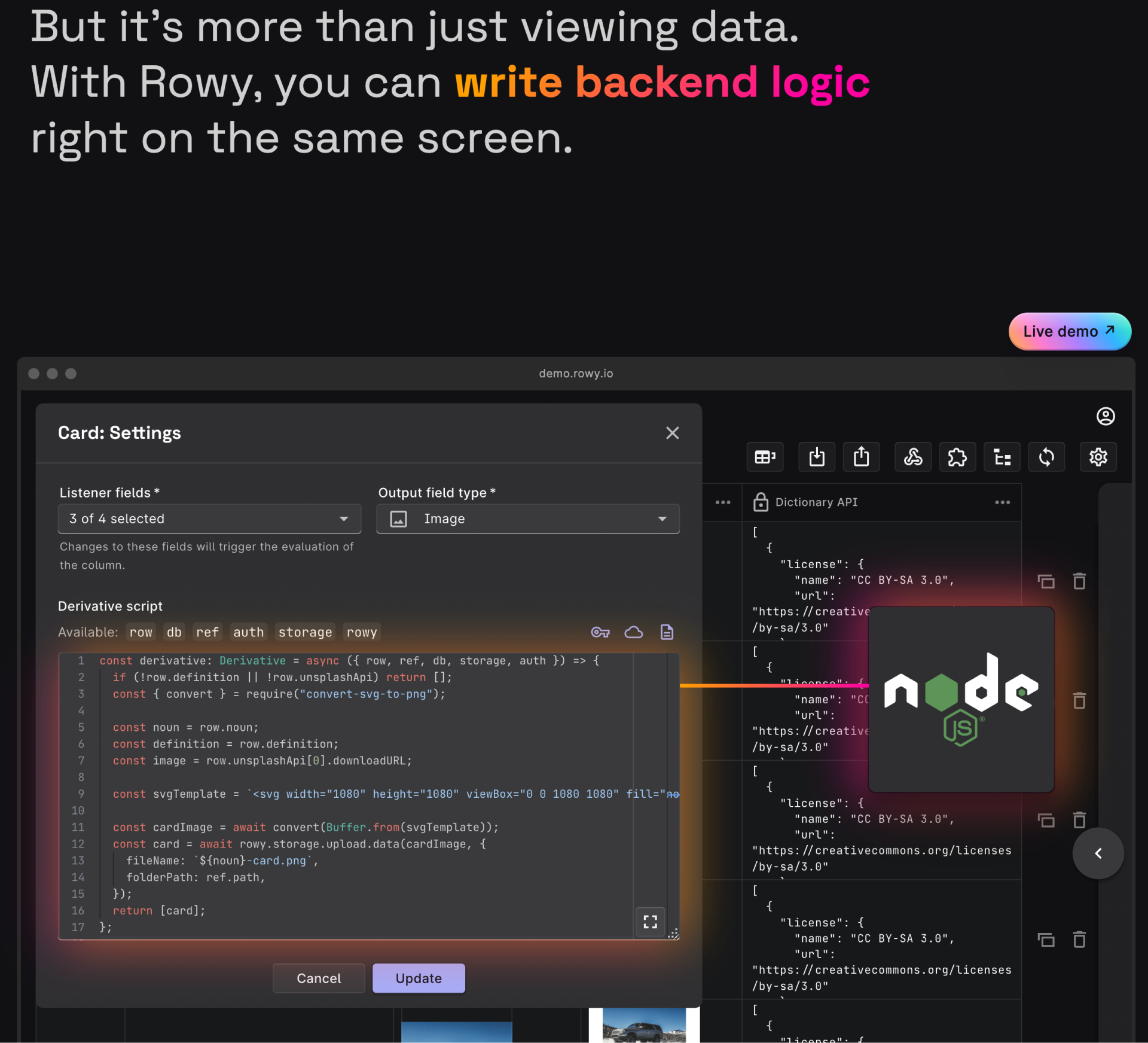
Because Rowy is a low-code backend at first it might seem like it is just another easy way to view Firestore. When in reality it is so much more than that! As you can see below you can write your own backend logic as well. They also have support coming for MongoDB and Postgres. I am excited to see what else they can add to this solution.
This one is for you Rust fans! SurrealDB is a SQL-style query language, with real-time queries. Because it offers a full graph database you can perform advanced queries and analysis. The really cool part is that it handles all the DIFFing and PATCHing for highly-performant web-based data syncing in realtime.
I couldn't talk about Xata without mentioning Monica Sarbu is the CEO. She is the former Director of Engineering and helped drive Elastic to IPO. Not only does Xata offer a Relational Database but it also has search Integrated. Now you see why it is important to understand the Elastic background. With database branching, type safety, built-in AI and more, Xata is just getting rolling and is checking off a lot of boxes! I also want to call out that they have one of the few public roadmaps so you can see what they are working on and the current changelog.
What to consider in the Future
So you now know the different choices that are available in the market, what is so compelling about some of these future market leaders?
Branch Preview Deployments
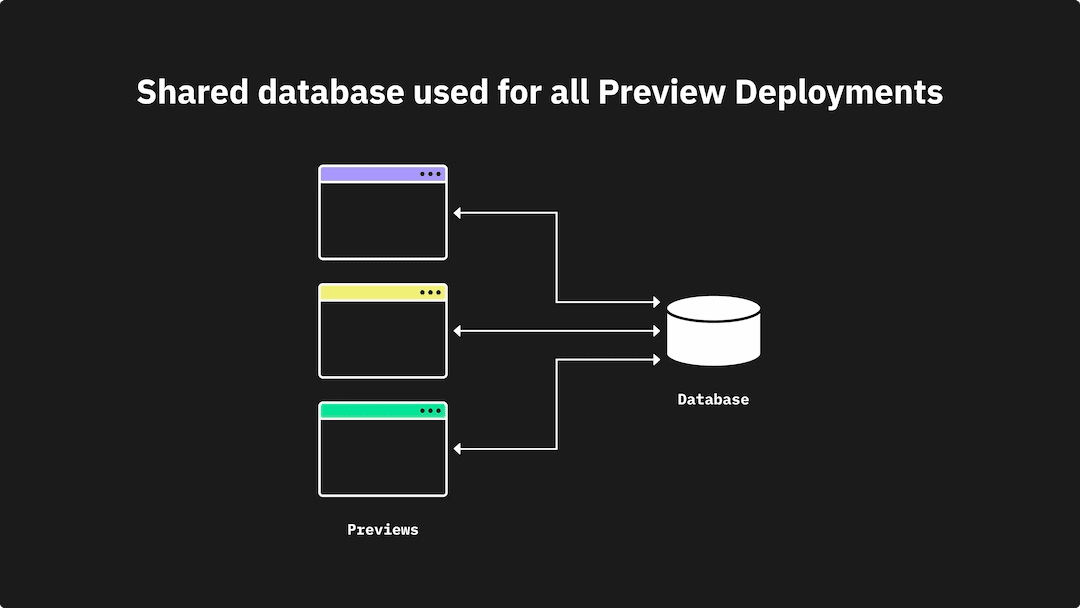
This is probably the biggest change you will see in the next 5 years when it comes to serverless databases. It is very common to when using to preview deployments for your frontend applications to only use a single database like below. This is a huge step forward from hitting any type of production database, but when previewing the deployment you might want to make new backend changes as well for this specific preview without affecting all other previews that other preview branches are working from.
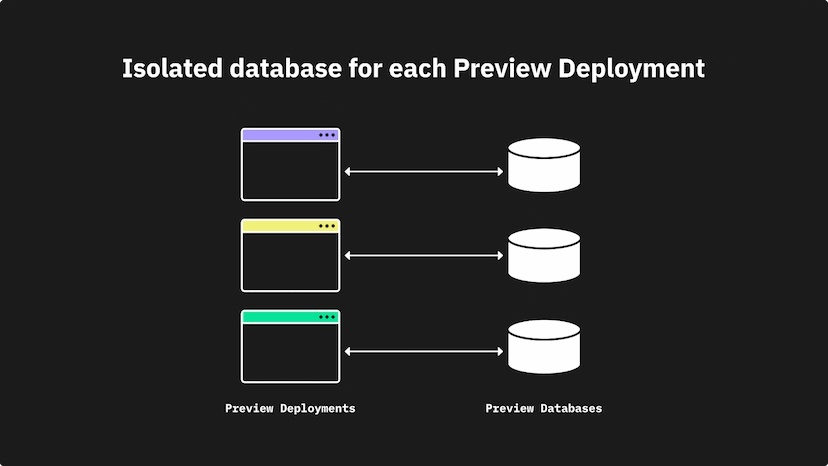
This is where a solutions like Neon and Xata are bringing the concept of previews to the next level and including a branch of you database as well to match! You can see in the below diagram you can have a database with specific migrations ready to take place when merge back to your main branch.
True Serverless
Gone are the days of managing a database server, we are now in the world of database as a service (DBaaS). As you can see from the above lists, there are a lot of new players in this multi billion dollar space. Moving to a serverless db allows developer to focus on building applications. As Cockroach Labs defines in What is a Serverless Database the key capabilities moving forward will be
- Little to no manual server management
- Automatic, elastic scale
- Built-in resilience and inherently fault-tolerant
- Always available and instant access
- Consumption-based rating or billing mechanism
Conclusion
There are a number of great databases that are well-suited for serverless and edge compute applications.
Remember these key factors:
Scalability: Your database needs to be able to scale to meet the demands of your application. Serverless and edge compute applications can be highly variable in terms of traffic, so you need a database that can scale up or down automatically.
Performance: Your database needs to be able to perform well under load. Serverless and edge compute applications can be very demanding on databases, so you need a database that can handle a lot of requests without sacrificing performance.
Ease of use: Your database needs to be easy to use. Serverless and edge compute applications are often developed by developers who are not database experts, so you need a database that is easy to learn and use.